Wayfinding with audio - designing 3D auditory displays

I had the privilege to join the Guide Dogs UK / Cities Unlocked project earlier to help push it through the next phase of development. Our team built, productized and integrated a collection of truly amazing services to turn the idea into reality.
From a user experience perspective, the turn-by-turn navigation functionality is by far the most complex. We went through a number of evolutionary and revolutionary steps during the past 6 months that this article will walk through. We learned a lot through the process and I believe we are still just scratching the surface of what's possible with auditory displays in real world products.
Current State of the Art
Turn-by-turn navigation is a relatively mature technology area, with a large pool of hardware and software solutions. There are a few common traits to most, if not all commercial offerings:
- A visual 2D/3D map with compass-based directional alignment.

- Visual/Voice search with visual list results to find intended destination.

- Live route guidance using a combination of skeuomorphic visuals: accurately scaled roadway maps and pictographs of lane position and direction of travel.

- Voice guidance that is a direct translation of the visual guidance.
- Nearly total reliance on roadway data[1] as the vector source for routing, regardless of transport mode: car, bus, bike, walking.
There are a few notable interactions that are pretty unique.
- Google maps (iOS) has haptic feedback for turn indications - Three vibrations for left, two vibrations for right. This is really useful for walking directions, you can almost leave your phone in your pocket.
- Apple Maps (Apple Watch) uses haptic feedback as well but 12 pulses for a right turn and three double pulses for a left turn.
Within the visually impaired community, two apps stand out from the rest:
- Blindsquare which leverages FourSquare and OpenStreetMaps for POI (Point-of-interest) data, and has smooth handoff to Apple or Google maps for turn-by-turn direction.
- SeeingEyeGPS is a fully baked navigation and POI explorer. It can also leverage FourSquare as a data source but handles it's own turn by turn directions.
Both apps rely on the phone's compass to find orientation and spoken language for relative direction. This is usually manifested by either clock-orientation (12 o'clock being straight ahead, and 6 o'clock being directly behind) or through cardinal orientation (north, south, east or west in addition to the user's current direction).
Cities unlocked introduces a new capability: highly accurate 3D spatial audio.
Lack of precision with spoken language
We struggled from the very beginning on finding a spoken language lexicon that could be both precise and brief. English is especially poor for this pursuit when it comes to wayfinding.
All GPS-based apps struggle with the same complexity, though for driving and sighted users, much of this can be masked by cognitive error correction based on visual landmarks.
If an app is telling you to turn right in 30ft, but the real turn is in 15ft due to GPS interference or LTE congestion, a sighted user can resolve the conflict quickly - the intersection will be in a slightly different place and they can quickly error-correct. For a visually impaired user, this can mean the difference between turning onto a path vs. the middle of a busy road.
Furthermore, when on a route that requires a long, straight segment, it can be very easy to question whether or not you're still on track. Has the app stopped? Have I overshot? We introduced a positive reinforcement feature called navigation sense to solve this problem.
In addition, we added a spoken reminder to users that they were still on the right path and the app is working: > "Continue towards Market St."We found ourselves over indexing on completeness and precision more and more.
"Turn left at the corner of Market St. and Pine St. in 152ft, then continue on Pine St. heading North."
But in practice, users had a hard time processing all of the details. The app was bombarding users with continual updates on GPS signal strength changes, waypoints, turns, location information and safety information. On some routes, the spoken audio would stack up with messages incoming faster than they could be spoken to the user.
Part of the solution to this problem came with technical improvements to both the application and services.
- Implementing configurable speech prosody (speed) in our text to speech engine to allow users to have more audio density.
- Kalman filtering allowed us to be much more resilient to GPS degradation, reducing the occurrence of verbal warnings dramatically.
- Client-side and service caching reduced command latency from several seconds to sub 250ms, increasing the reliability of location specific announcements.
- Improvements to the precision of the spatial audio engine eliminated the need for cardinal or clock-based directional verbiage.
- Adding huge amounts of GPS data for footpaths, building features and obstacles to OpenStreetMaps improved routing reliability and reduced noise from road vs. walkway deviations.
After months and months of improvements, the app "noise" was reduced dramatically. One of our most common commands, "What's around me?", responds with the 4 nearest points of interest in each direction around you. At the beginning of our work, it averaged almost 17 seconds to complete the spoken response. With technical improvements, we were able to reduce this to 12 seconds (30% better) at 1x prosody, down to 4 seconds (83% better) at 3x prosody.
The app was now usable. User feedback supported this, but we still had issues. There was still continual feedback that the app felt too verbose in some ways and too limited in others. We'd finally reach the point of diminishing returns with spoken language. It was time to look for other auditory means to convey information.
Non-verbal audio information
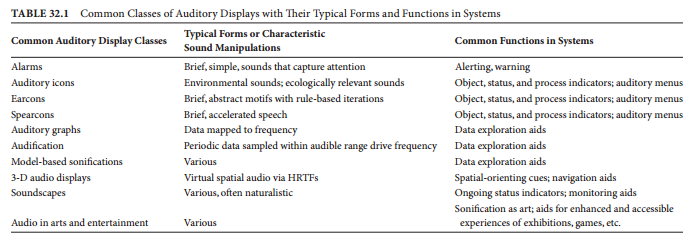
There is a wide base of academic research into auditory displays and methods that I was extremely fortunate to turn to our quest for improving the user experience. Alarms, earcons, auditory icons, audification, sonification, and soundscapes form the lexicon of non-verbal audio cues that one can harness in auditory displays.
 (Source)
(Source)
We ruled out alarms and spearcons early on, the former being far too startling and the latter still suffering from language shortcomings. Auditory icons were also ruled out as many of the concepts we have in the app are abstract, without good natural sound correlations.
So earcons and audification became the tools of choice for our experimentation.
Poor supplements to speech
We experimented with earcons to differentiate different types of POIs: landmarks, shops, hazards, etc. We call these the senses: location sense, information sense and safety sense. They were used as a supplement to the spoken name of the POI. Surprisingly, even with a small set of well-produced sounds, we found users didn't remember them and didn't find them valuable.
Similarly, we used this for navigation sense as an addition to speech directions during turn-by-turn navigation. But unlike the other senses, navigation sense was unique. It isn't directly paired to a verbal instruction, but rather a mode that can be toggled on and off by the user independently of spoken instructions.
This caused us some pain and complexity in the user interface, but also presented an opportunity. Since this sense was already decoupled from speech, how could we manipulate the relationship with speech and how would it affect user's ability to navigate safely, confidently and efficiently?
Experiment 1: Automatic activation
The first experiment was looking for ways to reduce the cognitive load for the user by automatically triggering navigation sense at known useful times: beginning a new journey, rerouting, and at turns. We knew users overwhelmingly triggered nav sense after these states, and indeed we found almost instantly that this was a much-improved experience. Navigation sense added more primary information (exact absolute direction) to spoken directions (relative instructions). My colleague Phong Cao Thai did an incredible job implementing this.
Experiment 2: Parallel playback
Until this point, we purposefully designed our audio engine to be single-channel to avoid cocktail party[2] overload, especially for critical safety information. We designed an interrupt-driven audio queue with command priorities for point of insertion. But once again, navigation sense didn't need to be played alone - it didn't interfere with speech or the other earcons.
So Andrei Ermilov extended our audio engine with an experimental second channel to enable nav sense to play in parallel. Once again, we immediately saw the positive impact on user experience: users could easily parse the very binary directional audio cue in parallel with spoken commands with little effort, thanks to the way our brain processes different kinds of sounds in different ways[3].
Experiment 3: "Always on"
Naturally, after enabling parallel playback and seeing the success of automatic activation, we pushed even further. What if we trigger nav sense after every change in our state machine? This turned out to be a step backward. The earcon we used wasn't designed to be played continuously. While we watched user safety and efficiency improve, we'd hit the noise threshold. It was just too intrusive and became an annoyance, even with the added benefits.
Why had we hit a point of diminishing returns? Would a new earcon help alleviate this problem?
Supplementing positional audio
We learned a number of lessons along the way with our "clip-clop" navigation sense sounds. Similar to the "Six principles of visual context" from Stephen Few, there seems to be a similar set of contextual traits that you can use for auditory displays.
- We knew that binary on/off sounds were just too finicky.
- We knew that constant bombardment of a repeating earcon became quickly annoying to users, outweighing the value.
- We knew that it would be possible to convey more information density through sound than speech if done well.
- Technically we could now play multiple streams at once, creating the need to be mindful of cocktail party effects.[2:1]
With a bit more research I ran across several interesting possibilities.
Using the concepts of dopplar effects to convey distance from target as seen here: http://sonification.de/handbook/index.php/chapters/chapter5/#S5.4
To keep things simple, and based on some prior research into error rates, I kept the number of initial steps to 5. The idea being to allow for quite a bit of deviation from target with subtle changes to the sound, but having enough steps to provide the illusion of a cascade of sound.

And the concept of relating size to sound through using volume, intensity and composition as seen here:
http://sonification.de/handbook/index.php/chapters/chapter5/#S5.3
I used this idea to form the idea of the cascade. Being that each sound layers on top of the previous to create a continuous compoisition for the user.

At this point I needed help from a professional audio designer. I reached out to my colleague Matthew Bennett, who has been almost secretly creating incredible audio experiences for Microsoft's biggest platforms.
Breaking conventions and moving forward
With a few weeks of iterations, Matthew landed on our first hit - a cascading, multi-step set of navigation sense sounds. We broke one major convention with this experiment: the closer to target, the less intense the sound. There was a lot of pushback to this design, but we were given the freedom and flexibility to try it! We got the sounds integrated into the app and you can hear the initial results:
It was a surprise to say the least. Even the designers were a bit taken with how well this worked even in it's first prototype integration.
So we upped the ante and re-enabled "always on":
It worked! User feedback was pretty immediate - the sounds were effective without being annoying, and communicated position and action for the user. While far from done, the cascading composition approach seems to be the winning entry.
Where to go from here and lessons learned
The new navigation sense exposed a slew of new bugs and limitations in the application that now need to be addressed:
- How "always on" is always-on? Should it ever be interrupted?
- How far can we push removing spoken language with the new navigation sense before it too reaches dimishing returns?
- Is 5 the right number of steps? Would a parametric compositional approach produce even better results than static samples?
- How can we integrate beat matching / sample alignment into the spatial audio engine?
(Updated 12/24/2020 - Links to Microsoft Developer Blog)
Footnotes
https://en.wikipedia.org/wiki/Comparison_of_web_map_services ↩︎
Cocktail Party Effect - http://sonification.de/handbook/index.php/chapters/chapter3/ ↩︎ ↩︎
Spoken and non-verbal audio processing - http://www.geog.ucsb.edu/~marstonj/PAPERS/2007_Marston_etal_%20JVIB.pdf ↩︎



{kind=link}